 Korte byte: Webcrawler er et program, der gennemsøger Internettet (World Wide Web) på en forudbestemt, konfigurerbar og automatiseret måde og udfører en given handling på gennemsøgt indhold. Søgemaskiner som Google og Yahoo bruger spidering som et middel til at levere opdaterede data.
Korte byte: Webcrawler er et program, der gennemsøger Internettet (World Wide Web) på en forudbestemt, konfigurerbar og automatiseret måde og udfører en given handling på gennemsøgt indhold. Søgemaskiner som Google og Yahoo bruger spidering som et middel til at levere opdaterede data.
Webhose.io, et firma, der giver direkte adgang til live data fra hundreder af tusinder af fora, nyheder og blogs, offentliggjorde den 12. august 2015 artiklerne, der beskriver en lille, multi-threaded webcrawler skrevet i python. Denne python-webcrawler er i stand til at gennemgå hele internettet for dig. Ran Geva, forfatteren af denne lille python-webcrawler siger, at:
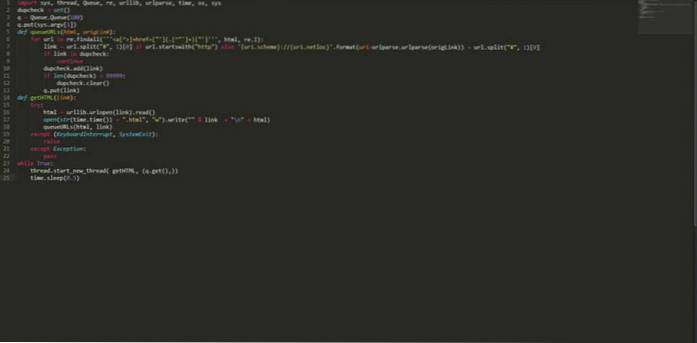
Jeg skrev som "Dirty", "Iffy", "Bad", "Not very good". Jeg siger, det får jobbet gjort og downloader tusinder af sider fra flere sider i løbet af få timer. Ingen opsætning er påkrævet, ingen ekstern import, bare kør følgende pythonkode med et frøsted og læn dig tilbage (eller gå og gør noget andet, fordi det kan tage et par timer eller dage afhængigt af hvor meget data du har brug for).Den pythonbaserede multi-threaded crawler er ret enkel og meget hurtig. Det er i stand til at detektere og eliminere duplikerede links og gemme både kilde og link, som senere kan bruges til at finde indgående og udgående links til beregning af siderangering. Det er helt gratis, og koden er angivet nedenfor:
import sys, thread, Queue, re, urllib, urlparse, time, os, sys dupcheck = set () q = Queue.Queue (100) q.put (sys.argv [1]) def queueURLs (html, origLink): til url i re.findall ("] + href = ["'] (. [^"'] +) ["']", html, re.I): link = url.split ("#", 1) [0] hvis url.begynder med ( "http") ellers 'uri.scheme: // uri.netloc' .format (uri = urlparse.urlparse (origLink)) + url.split ("#", 1) [0] hvis link i dobbelt kontrol : fortsæt dupcheck.add (link) hvis len (dupcheck)> 99999: dupcheck.clear () q.put (link) def getHTML (link): prøv: html = urllib.urlopen (link) .læs () åben (str (time.time ()) + ".html", "w"). skriv (""% link + "\ n" + html) queURURLs (html, link) undtagen (KeyboardInterrupt, SystemExit): hæv undtagen Undtagelse: pass mens True: thread.start_new_thread (getHTML, (q.get (),)) time.sleep (0.5) Gem ovenstående kode med et navn, lad os sige “myPythonCrawler.py”. For at begynde at gennemgå ethvert websted skal du bare skrive:
$ python myPythonCrawler.py https://fossbytes.com
Læn dig tilbage og nyd denne webcrawler i python. Det downloader hele webstedet for dig.
Bliv pro i Python med disse kurser
Kan du lide denne døde enkle pythonbaserede multi-threaded webcrawler? Lad os vide i kommentarer.
Læs også: Sådan oprettes bootbar USB uden software i Windows 10


